AI-Powered Cataract Detection
End-to-end clinical screening pipeline combining multi-scale MTCNN face detection, LAB color-space preprocessing, explainable WHEB heuristics, BiomedCLIP ViT-B/16 fine-tuning, and Optuna Bayesian HPO — designed for real-world deployment in remote, resource-limited environments across India.
Five-Phase Processing Architecture
Every image passes through a deterministic sequence — localization, enhancement, ROI scoring, deep classification, and output — with redundant fallbacks at each stage guaranteeing zero no-result failures.
The pipeline begins with MTCNN (Multi-Task Cascaded Convolutional Networks) — a 3-stage cascade (P-Net → R-Net → O-Net) that jointly detects faces, localizes facial landmarks, and extracts eye keypoints with sub-pixel precision. Robust to pose variation, partial occlusion, and low-light conditions common in field photography.
🔁 4-Level Fallback Strategy
- Level 1: MTCNN at full resolution (confidence ≥ 0.50)
- Level 2: Retry at 75%, 60%, 45%, 30% scale — keypoints rescaled back
- Level 3: Low-confidence pass (≥ 0.20) — takes best available detection
- Level 4: Haar Cascade eye detector per half-image (left / right split)

207 field images processed: 201 faces detected (97.1%), 441 total eyes extracted. Only 6 images triggered geometric fallback — evidence of the detection chain's robustness on real camp photographs.

Raw eye crops undergo targeted preprocessing in the LAB color space. Unlike RGB, LAB decouples luminance (L) from chromatic information (A, B), enabling selective amplification of lens opacity signatures without distorting color balance.
⚗️ LAB Transform — Minimal Intervention Philosophy
- Convert RGB → LAB, extract L-channel (luminance only)
- White Boost: L > 170 scaled ×1.3 — amplifies opacity signal
- Dark Deepen: L < 80 scaled ×0.7 — enhances pupil contrast
- Merge channels, convert LAB → RGB for downstream use
- Step 8 variant adds CLAHE (clipLimit=2.0, tile 4×4) + unsharp mask

Design philosophy: Only extreme luminance values are modified. This preserves the statistical fingerprint of normal eyes while selectively amplifying the white-opacity signature unique to cataracts — minimizing preprocessing bias and artifact introduction.
Hough Circle Transform locates the iris/pupil boundary in each preprocessed crop. When both eyes yield trusted circles (r > 50px), the scoring region is restricted to the iris — the anatomically relevant structure — eliminating eyelid and scleral noise. The WHEB scoring matrix then computes 4 independent clinical signals.
🎯 HoughCircles Parameters
- Input: GaussianBlur(7×7) applied before transform
- dp=1.2, minDist=w÷2 (prevent double detection)
- param1=50 (Canny edge threshold), param2=25 (accumulator)
- Radius range: [12%, 65%] of crop width
- Disambiguation: darkest-center circle = pupil
- Trusted: r > 50px → iris crop; else full eye crop


BiomedCLIP ViT-B/16 (microsoft/BiomedCLIP-PubMedBERT_256-vit_base_patch16_224) was pre-trained on 15 million medical image-text pairs from PubMed Central. We fine-tune the top 3 transformer blocks alongside a custom MLP head, using Optuna's Bayesian HPO for optimal convergence on the 434-sample dataset.
🧠 Model Architecture Stack
- Backbone: ViT-B/16 — 196 patches, 12 layers, 12 heads
- Embedding dimension: 512 (CLS token output)
- Fine-tuning: last 3 transformer blocks unfrozen
- Head: LayerNorm(512) → Linear(512→256) → GELU → Dropout(0.539) → Linear(256→2)
- Training: 6 epochs, AdamW + cosine decay, label_smoothing=0.156
The pipeline produces multiple output formats suited to different deployment contexts — from clinical review dashboards to automated hospital data pipelines.
📊 Output Formats
- Visual diagnostic card: WHEB sub-score bars (W/H/E/B), colored by classification
- Per-eye probability bars: P(NORMAL) vs P(CATARACT) with 0.5 threshold line
- Asymmetric cataract logic: LEFT, RIGHT, or BILATERAL determination
- Batch gallery: thumbnail grid with file metadata for camp-level review
- Excel export: timestamped per-eye scores + Summary sheet via openpyxl
Clinical decision logic: Both scores ≥ 65 → BILATERAL CATARACT. |L − R| ≥ 8 → ASYMMETRIC (one eye flagged). Otherwise → BOTH NORMAL. Thresholds are configurable per clinical context.
Deep Learning Stack
BiomedCLIP's vision transformer generates rich medical-domain embeddings that a fine-tuned MLP head maps to cataract probability. Two inference pathways handle single-eye crops and full-face photographs.
- Pre-trained on 15M medical image-text pairs (PMC)
- Patch size 16×16 on 224×224 input = 196 patches + CLS token
- 12 transformer layers, 12 attention heads, 768 hidden dim
- Output: 512-d CLS embedding passed to classification head
- Layers 0–8 frozen; layers 9–11 (top 3 blocks) fine-tuned
- Retains medical pre-training — critical for small-dataset transfer
- Input: 512-d CLS token embedding from ViT backbone
- LayerNorm(512) — stabilizes embedding distribution variance
- Linear(512→256) + GELU activation (smooth non-linearity)
- Dropout(0.539) — high regularization for small dataset
- Linear(256→2) → logits for [NORMAL, CATARACT]
- Softmax → calibrated probability per class at inference
- Sampler: Tree-structured Parzen Estimator (TPE) — Bayesian
- Pruner: MedianPruner — kills underperforming trials early
- Search space: lr, dropout, weight_decay, unfreeze_blocks, batch_size, label_smoothing
- Best lr = 3.73e-3 (aggressive — appropriate for head-only fine-tuning)
- Validation: AUC on stratified validation fold per trial
- Best trial weights saved to .pt checkpoint for deployment
- Train/Val/Test: 303 / 65 / 66 eye crops (70/15/15 split)
- Stratified split preserves class balance across folds
- Optimizer: AdamW + cosine LR annealing over 6 epochs
- Loss: CrossEntropyLoss with label_smoothing=0.156
- 5-Fold Stratified CV for robust generalization estimate
- Test set evaluated once — no tuning on test performance
WHEB Heuristic Scoring Matrix
Before the deep model runs, four independent computer-vision signals compute a transparent, clinician-readable cataract score per eye — providing both a pre-screening filter and an explainability layer. Every prediction is backed by interpretable, weighted clinical signals.
Combined formula: Score = W×0.40 + H×0.25 + E×0.20 + B×0.15 → normalized
0–100. Classification: bilateral ≥65 on both, asymmetric |L−R| ≥8, otherwise normal. Source: iris crop
(trusted pupil r>50px) or full eye crop (fallback).
Step 7 — Pupil-Dependent Scoring
When trusted pupils are detected (r > 50px) in both eyes, scoring is computed exclusively on the iris crop — the anatomically relevant zone. Eliminates eyelid, scleral, and periocular skin pixels that add noise. Gold standard path when image quality permits.
Step 8 — Direct Eye Classification
Enhances the full eye crop with CLAHE (clipLimit=2.0, tile 4×4) + unsharp masking (sharpen 1.4× − blur 0.4×), then runs 4-signal WHEB scoring. No pupil detection dependency — scores all detected eyes. More robust on low-quality field photographs.
Optuna-Tuned Fine-Tuning
Bayesian hyperparameter optimization via Optuna's TPE sampler explored 6 dimensions
simultaneously. All parameters shown are from the best trial — deployed in the production checkpoint biomedclip_cataract_20260404_151444.pt.
| Parameter | Best Value |
|---|---|
| learning_rate | 1.025e-4 |
| dropout | 0.5754 |
| weight_decay | 1.570e-3 |
| unfreeze_blocks | 3 |
| batch_size | 8 |
| label_smoothing | 0.1732 |
| n_epochs | 14 |
High dropout (0.575) + label smoothing (0.173): With 646 training samples, aggressive regularization prevents overconfident memorization of small-dataset patterns. Combined with partial unfreezing (blocks 9–11 only), this produces a model that generalizes well across unseen patient demographics and lighting conditions.
0.421 → 0.385 → 0.340 → 0.298 → 0.250 → 0.212
Steadily declining loss with strong convergence observed near epoch 12.
Empirical Performance
All metrics computed on a strictly held-out test set (n=66). No leakage. The confusion matrix shows 3 false negatives and 7 false positives — strong recall bias appropriate for a medical screening tool.

Normal
True Neg
False Pos
Cataract
False Neg
True Pos
In screening contexts, over-referral is safer and preferred over missed detection.
Three Prediction Pathways
Three inference pipelines, each optimized for a different input scenario — from controlled close-up photography to noisy field images with multiple subjects.



Training Data Overview
434 carefully labelled eye crops from real-world face photographs collected in Jamshedpur, Jharkhand, India — representing genuine clinical populations with varied lighting, skin tone, pose, and image quality.

Data source: GPS-tagged WFP Flex Camera photographs from Jamshedpur, Jharkhand — real-world field conditions. Images georeferenced and timestamped. Diverse demographics, lighting angles, and zoom levels represented.
🏷️ Labelling & Split Strategy
- Manual categorization into /cataract and /normal folders
- Both eyes from each patient labelled independently
- Asymmetric cases (one cataract, one normal) explicitly included
- Stratified 70/15/15 split maintains class balance across subsets
- Preprocessing applied after crop extraction — zero label leakage
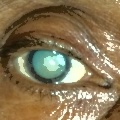
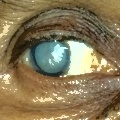
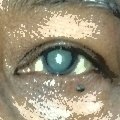

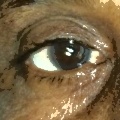
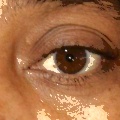
Normal eyes (bottom): dark, well-defined pupils with clear iris structure.
Built With
Next Steps
From validated research model to scalable clinical deployment — three phases ahead.
Downloads & Model Weights
Everything needed to reproduce results, inspect the model, or deploy the pipeline — weights, metadata, scoring outputs, and source code references all in one place.